moe - mixture of experts
· 4 min read
hey, i was trying out the composer 1 in cursor, and was trying to understand how is inference super fast and even the code is very accurate at the same time, and how much does it cost (interms of gpus usage) and how did they scale to all cursor users.
so i started digging into a few articles and papers, got my hands on a few open source models like ibm-granite/granite-3.1 and mixtral 8x7b which are sparse mixture of experts models. but then, i didnt understand how does it work, was wondering what is 8x7b? is it 8 times better than 7b? or 8x the size of 7b? well, the model has 8 experts, each with 7 billion parameters mistral style model. what the hell are these experts?
lets understand a little more about this to make sense of it.
- experts: its a feed forward neural net and can be “n” in a single layer but in our above case, its 8 experts (ffnn) in a single layer.
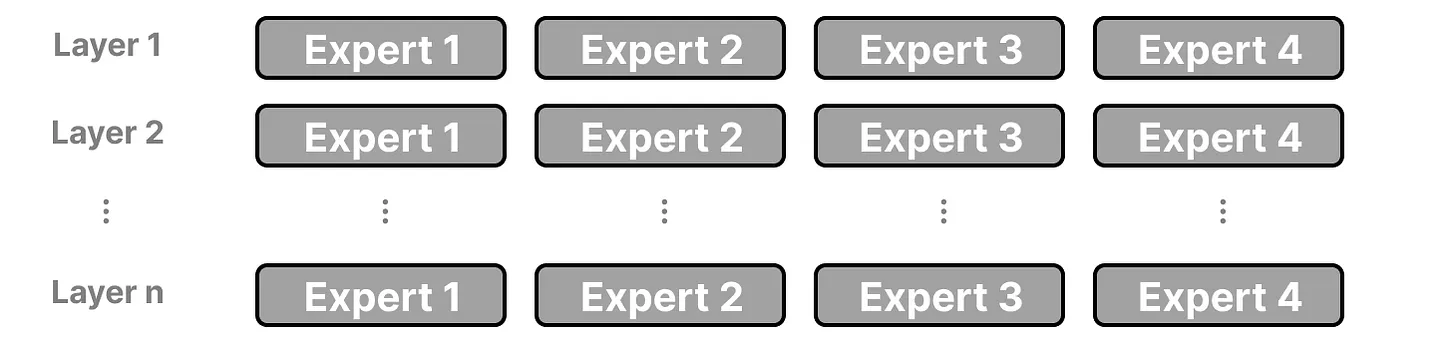
does it mean, they are experts in different tasks? no, they are not specialized in specific domain, instead they learn syntactic information on token level.

but how are these experts selected? for that we have:
- gating network (router): it is a feed forward neural net that is responsible for choosing which experts should process the each token. structure is very simple, a single linear layer + softmax/top-k selection of experts nothing complex.
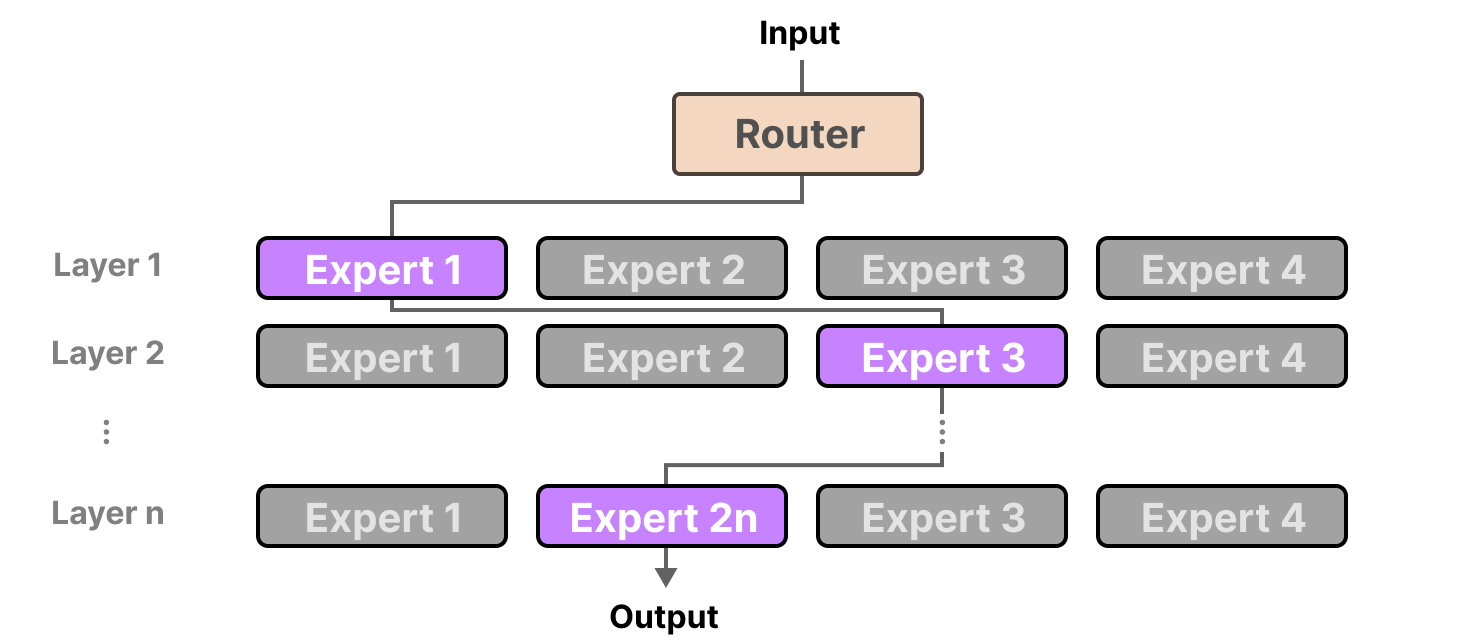
this seemed pretty interesting for me, so i started training a very small mixture of experts model locally to understand, replicate the gating behaviour, when experts collapse, how does the load balancing work across the experts, and how are these specialized over the time.
components:
- gating network: single linear layer + softmax/top-k over experts
- experts: 3 MLPs (multi layer perceptrons - ffnn)
- each expert is a simple
2 → 32 → 3MLP + ReLU activation
- each expert is a simple
- loss function:
cross entropy loss + load balancing x (0.1)- cross entropy loss
- load balancing loss
after training for 100 epochs, ive observerd the following:
at epochs (1-15):
Epoch 1: [0.012, 0.353, 0.634]
Epoch 15: [0.000, 0.333, 0.667]

- the expert 2 dominated between the 3 experts
- the load balancing loss was very high, indicating that the experts were not balanced
- route converges to a single easy expert
why?
- the ce (cross entropy) loss dominated early in training
- gating picks whichever expert gives the lowest loss in training
- without load balancing loss, the model would converge to a single expert
this actually mirrors the behviour of bigger models but at scale, on how the experts collapse and how load balancing works across the experts.
at epochs (16-48):
Epoch 48: [0.331, 0.054, 0.615]
- the load balancing fight still exists, as the gating is still routing most of the tokens to expert 2, but as the load balancing loss starts pushing the token to expert 0, the expert 2 is little bit pushed back and the expert 1 also drops sharply from 0.6 to 0.05.
why?
- the lb loss penalizes the gating as:
avg_usage != [1/3, 1/3, 1/3] (uniform distribution)
at epoch (100):
Epoch 100: [0.342, 0.239, 0.418]
- the load balancing loss is now very low, indicating that the experts are balanced.
- no collapse of experts
- ce stays low
33/33/33 distribution is ideal, but very unrealistic as in real world, the experts naturally specialize in different regions of tokens space as shown in the above image.
coming back to where we started on how composer 1 is able to scale to all cursor users, and how is inference super fast and even the code is very accurate at the same time.
- the model is also a mixture of experts model, not mentioned how many experts as its not public yet, but its a sparse mixture of experts model with RL post training to be better at agentic tasks, mainly in parallel tool calling (read, write, search code, etc.)

im going to explore further into RL post training for moe models in a separate blog. thanks for reading!
*some images are used from internet, credits to the original authors.